
你是否遇到过这些场景?看了一段很长的视频讲座,想把内容整理成文字笔记;拿到一段会议录音,需要快速转写成文稿;找到一个外文视频,想要翻译成中文……手动听写一小时的视频,可能要花三四个小时。
今天介绍一个用 Python + OpenAI Whisper 搭建的视频转文字工具,只需几行命令就能把视频里的语音自动识别为文字,支持中文、英文、日文等 99 种语言,还能自动断句分段、生成 SRT 字幕。
一、这个工具能做什么
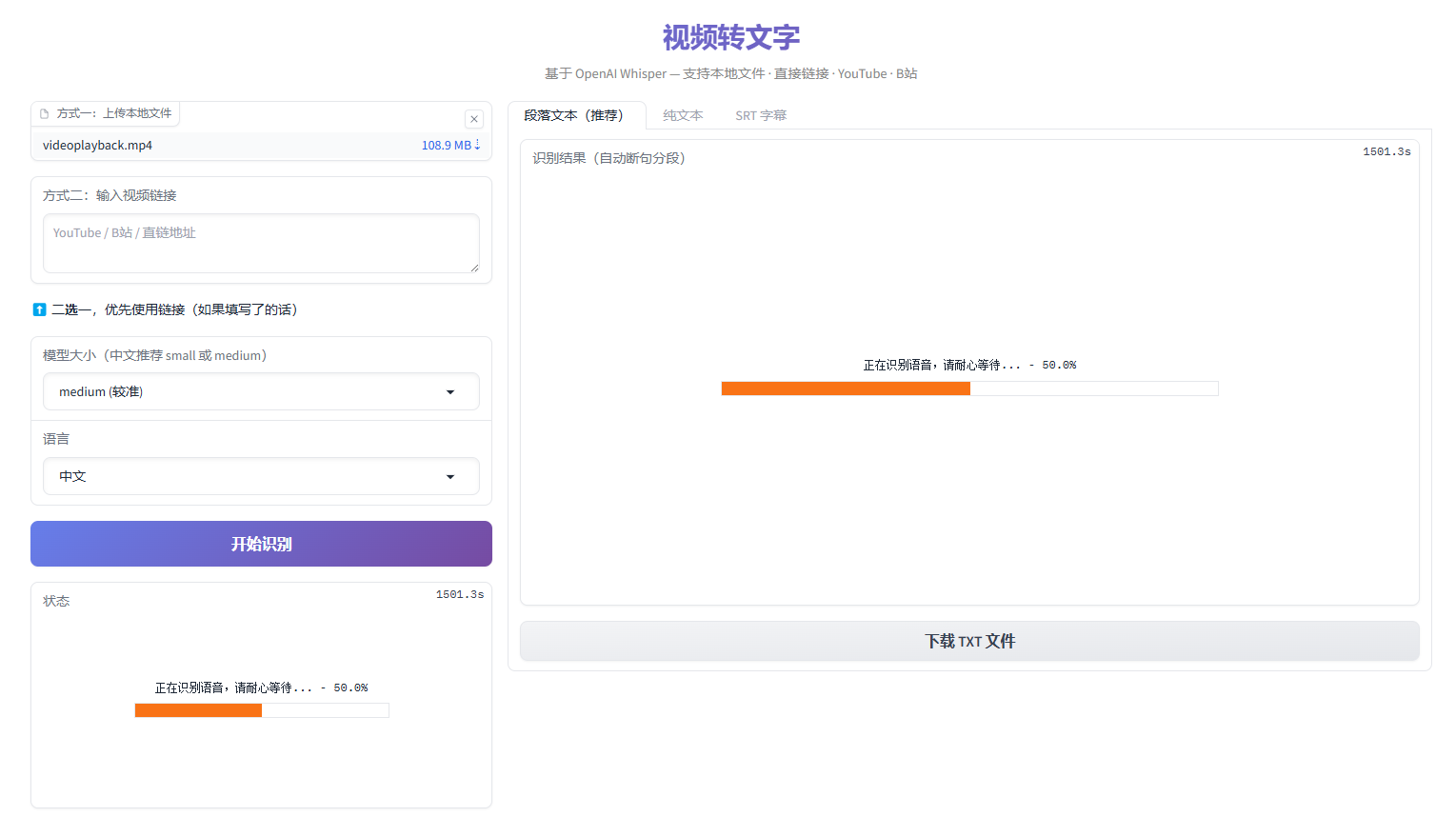
先看看最终效果。运行后浏览器会打开一个网页界面,你可以:
上传本地视频/音频文件:支持 mp4、avi、mkv、mov、mp3、wav、flac 等常见格式
输入在线链接:支持 YouTube、B站、抖音等平台链接,也支持直接的视频文件 URL
自动识别语音:基于 OpenAI 开源的 Whisper 模型,准确率业界领先
智能断句分段:根据标点符号自动将连续文本分成段落,方便阅读
生成 SRT 字幕:输出标准字幕格式,可直接导入 Premiere、剪映等剪辑软件
支持 99 种语言:中文、英文、日文、韩文、法文、德文等,也可以自动检测语言
整个识别过程完全在本地运行,不需要联网(首次下载模型除外),不需要 API Key,不需要付费,隐私数据不会上传到任何服务器。
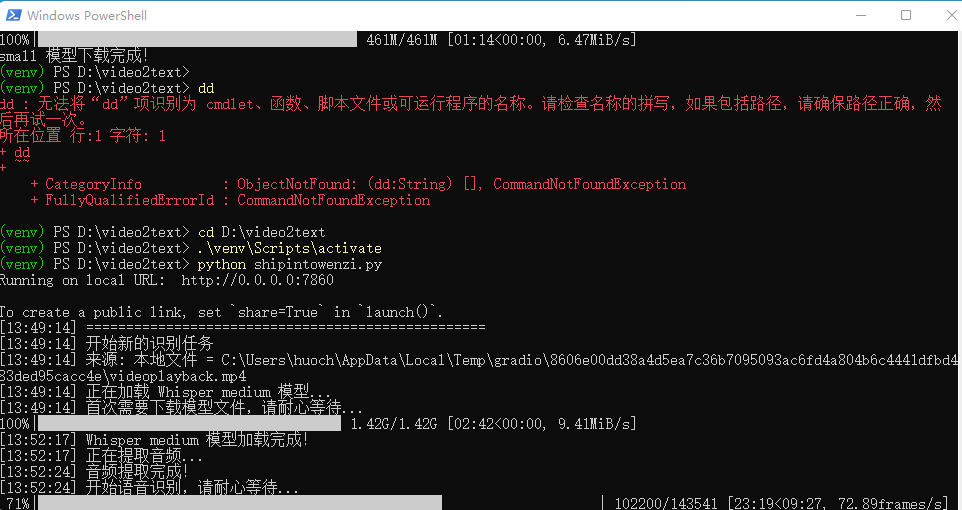
运行中的界面:
二、技术方案与架构
整体流程非常清晰:
视频文件/在线链接 → 提取音频(FFmpeg) → 语音识别(Whisper) → 文字/SRT字幕
核心技术栈
| 组件 | 作用 | 说明 |
|---|---|---|
| OpenAI Whisper | 语音识别引擎 | OpenAI 开源的通用语音识别模型,支持 99 种语言,准确率业界领先 |
| FFmpeg | 音视频处理 | 从视频中提取音频,转码为 Whisper 需要的 16kHz WAV 格式 |
| MoviePy | Python 音视频库 | 封装了 FFmpeg 的 Python 接口,方便提取音频 |
| Gradio | Web 界面框架 | 快速生成一个简洁的网页操作界面 |
| yt-dlp | 在线视频下载 | 支持 YouTube、B站等 1000+ 平台的视频下载 |
三、环境准备(Windows 完整教程)
3.1 安装 Python
前往 Python 官网 下载 Python 3.9 或更高版本。
重要:安装时务必勾选 Add Python to PATH,否则后续命令无法识别 Python。
安装完成后,打开 PowerShell 验证:
python --version # 输出类似:Python 3.11.5
3.2 安装 FFmpeg
FFmpeg 是处理音视频的核心工具,推荐用 Scoop 安装(最省心):
# 安装 Scoop(Windows 包管理器,只需执行一次) Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser Invoke-RestMethod -Uri https://get.scoop.sh | Invoke-Expression # 用 Scoop 安装 FFmpeg scoop install ffmpeg # 验证安装 ffmpeg -version
如果你更喜欢手动安装,也可以从 FFmpeg GitHub Releases 下载编译好的版本,解压后将 bin 目录添加到系统 PATH 环境变量中。
四、安装 Python 依赖
4.1 创建项目目录
# 创建项目文件夹(注意:路径不要包含中文字符) mkdir D:\video2text cd D:\video2text # 创建虚拟环境 python -m venv venv # 激活虚拟环境 .\venv\Scripts\activate
激活后命令行前面会出现 (venv) 字样,表示虚拟环境已生效。
提示:每次打开新的 PowerShell 窗口运行项目,都需要先执行 .\venv\Scripts\activate 激活虚拟环境。
4.2 安装依赖包
# 一行命令安装所有依赖(使用清华镜像加速) pip install openai-whisper gradio moviepy yt-dlp requests -i https://pypi.tuna.tsinghua.edu.cn/simple
各依赖包的作用:
openai-whisper:Whisper 语音识别模型gradio:Web 界面框架moviepy:音视频处理(提取音频)yt-dlp:下载 YouTube、B站等平台视频requests:下载直接视频链接
五、完整代码
在 D:\video2text 目录下新建一个 app.py 文件,扫描下载app.py无错源代码:

六、使用方法
6.1 启动程序
# 进入项目目录 cd D:\video2text # 激活虚拟环境 .\venv\Scripts\activate # 运行程序 python app.py
启动成功后终端会显示:
Running on local URL: http://0.0.0.0:7860
浏览器会自动打开 http://localhost:7860,如果没有自动打开,手动复制地址到浏览器访问即可。
6.2 操作步骤
输入源文件:上传本地视频文件,或在链接输入框中粘贴视频 URL
选择模型:推荐选择
small(日常使用)或medium(重要内容)选择语言:中文视频选「中文」,不确定就选「自动检测」
点击「开始识别」:等待处理完成
查看结果:在右侧 Tab 中选择「段落文本」查看带标点断句的识别结果
导出:点击「下载 TXT 文件」或「下载 SRT 文件」保存到本地
6.3 两种输入方式
| 方式 | 适用场景 | 支持范围 |
|---|---|---|
| 上传本地文件 | 视频在自己电脑上 | mp4, avi, mkv, mov, mp3, wav, flac 等 |
| 输入链接 | 网上看到的视频 | YouTube、B站、抖音、直接的 .mp4 URL |
两种方式二选一即可。如果同时填写了链接和上传了文件,优先使用链接。
6.4 输出说明
段落文本:根据标点符号自动断句分段,每段之间有空行分隔,最适合阅读和整理
纯文本:所有识别文字连在一起,没有分段
SRT 字幕:标准字幕格式,包含每句话的开始时间和结束时间,可导入剪辑软件
七、模型选择指南
Whisper 提供了 5 个不同大小的模型,在速度和准确率之间有不同的取舍:
| 模型 | 参数量 | 文件大小 | CPU 耗时(10分钟视频) | 中文标点效果 | 推荐场景 |
|---|---|---|---|---|---|
| tiny | 39M | 75MB | 约 30 秒 | 较差 | 快速测试 |
| base | 74M | 142MB | 约 1 分钟 | 一般 | 对精度要求不高 |
| small | 244M | 466MB | 约 3~5 分钟 | 较好 | 日常推荐 |
| medium | 769M | 1.5GB | 约 10~15 分钟 | 很好 | 重要内容 |
| large | 1550M | 2.9GB | 约 30 分钟+ | 最好 | 专业字幕制作 |
建议:日常使用首选 small 模型,它在速度和准确率之间取得了最佳平衡。中文识别的标点和断句效果明显优于 tiny 和 base。如果有 NVIDIA 显卡,识别速度会快 5~10 倍。
首次使用注意
第一次选择某个模型时,程序会自动从网上下载模型文件。不同模型的下载大小不同:
tiny:75MB,秒下
base:142MB,很快
small:466MB,需要几分钟
medium:1.5GB,需要耐心等待
large:2.9GB,建议提前下载
下载完成后模型会缓存在 C:\Users\你的用户名\.cache\whisper\ 目录下,后续使用无需重复下载。也可以手动提前下载:
# 手动预下载 small 模型
python -c "import whisper; whisper.load_model('small'); print('下载完成')"八、常见问题与解决方案
Q1:识别出来的文字没有标点符号
原因:你用的是 tiny 或 base 模型,这两个模型对中文标点的识别能力很弱。
解决:切换到 small 或 medium 模型重新识别,标点和断句效果会大幅提升。
Q2:启动后终端没有任何输出,一直在等待
原因:很可能是首次下载模型文件,程序在静默下载中。
验证方法:打开文件资源管理器,进入 C:\Users\你的用户名\.cache\whisper\ 目录,看是否有 .pt 文件正在变大。如果文件大小在增长,说明正在下载,耐心等待即可。
Q3:报错 ModuleNotFoundError: No module named 'whisper'
原因:没有激活虚拟环境,或者依赖没有安装成功。
解决:
# 确保先激活虚拟环境 .\venv\Scripts\activate # 重新安装依赖 pip install openai-whisper gradio moviepy yt-dlp requests -i https://pypi.tuna.tsinghua.edu.cn/simple
Q4:项目路径包含中文字符导致报错
原因:Python 的部分库在处理中文路径时会出现编码错误。
解决:将项目放在纯英文路径下,例如 D:\video2text。
Q5:没有 NVIDIA 显卡能用吗?
完全可以。Whisper 支持 CPU 运行,只是速度比 GPU 慢一些。10 分钟的视频用 small 模型在 CPU 上大约需要 3~5 分钟,完全可接受。
Q6:如何生成公网链接分享给别人用?
在代码最后一行把 share=False 改成 share=True:
app.launch(share=True)
这样会生成一个临时的公网链接(72小时有效),任何人都可以通过这个链接使用你的工具。
Q7:YouTube 链接下载失败
确保 yt-dlp 是最新版本:
pip install --upgrade yt-dlp -i https://pypi.tuna.tsinghua.edu.cn/simple
九、总结
本文介绍了一个基于 Python + OpenAI Whisper 的视频转文字工具,具备以下特点:
完全免费、本地运行:不需要 API Key,不需要联网,数据不上传
支持多种输入方式:本地文件上传 + 在线链接(YouTube、B站等)
99 种语言支持:中文、英文、日文、韩文等,可自动检测
智能断句分段:根据标点自动将连续文本分成可读段落
SRT 字幕导出:生成标准字幕文件,可导入剪辑软件
Web 操作界面:浏览器打开即用,操作简单直观
带日志和错误处理:每一步都有实时进度显示,出错不会卡住
无论是整理视频笔记、制作字幕、还是转写会议录音,这个工具都能帮你节省大量时间。赶紧动手试试吧!